
1. 로그·이벤트 데이터 기반 사용자 행동 분석
실제 서비스에서 발생하는 대용량 로그/이벤트 데이터를 효율적으로 분석하기 위해서는 표본추출(sampling), 분포 이해, 이상치 탐지 등의 통계 개념이 필수적입니다. 데이터 양이 방대하면 무작위 샘플링으로 대표 표본을 뽑아 분석하는 것이 비용·속도 측면에서 효율적입니다. 예를 들어, 데이터의 일부(샘플)만 뽑아 전체를 대표하게 분석할 수 있습니다double-d.tistory.com. 추출 방법으로는 단순 무작위(SRS), 층화(stratified), 집락(cluster) 샘플링 등이 있으며, 대표성을 확보하는 기준을 명확히 해야 합니다.
데이터 분포를 파악하면 사용자 행동 패턴을 이해하는 데 도움이 됩니다. 로그 데이터는 종종 **왜도(skewed)**가 크고 긴 꼬리를 가지므로, 평균(mean)과 중앙값(median) 위치, 모드(mode) 간 관계를 주시해야 합니다. 예를 들어 좌우대칭 분포이면 평균≈중앙값이지만, 한쪽으로 치우치면 평균이 중앙값보다 더 꼬리에 영향을 받아 변화합니다openstax.org. 따라서 왜도가 큰 이벤트 데이터에서는 평균보다 중앙값이나 백분위수(percentile, 예: 95% 퍼센타일) 기반 지표를 같이 살펴야 전체 사용자가 체감하는 전형적인 값을 더 잘 나타낼 수 있습니다.
이상치 탐지도 중요합니다. 로그에서 갑작스런 에러 스파이크나 극단적 지연값을 찾아야 문제를 빨리 해결할 수 있습니다. 정규 분포를 가정할 수 있다면 Z-점수(Z-score) 기법을 사용하여 평균으로부터 3σ(표준편차) 이상 벗어나는 값을 이상치로 간주할 수 있습니다velog.io. 분포가 비정규이거나 치우침이 심한 경우에는 IQR(사분위범위) 기반 방법을 사용합니다. 즉, 제1사분위(Q1) − 1.5×IQR 이하, 제3사분위(Q3) + 1.5×IQR 이상인 값들을 이상치로 처리합니다velog.iovelog.io. 이를 통해 로그 데이터의 노이즈(예: 잘못된 이벤트)나 시스템 장애 시 발생하는 특이 패턴을 검출할 수 있습니다.
2. A/B 테스트 설계 및 해석
제품 기능 개선을 위한 A/B 테스트에서는 적정 표본 크기와 통계적 유의성(유의확률 p-value), 효과 크기(effect size) 등을 고려해야 합니다. 먼저, 테스트를 설계할 때 모수(예: 기본 전환율), 원하는 최소 검출 효과 크기, 유의수준(예: 5%)과 검정력(power, 보통 80~90%)을 정해야 합니다. 그런 뒤 표본수 계산을 통해 필요한 관측 횟수를 산출합니다medium.cominvespcro.com. 표본수가 적으면 실제 차이가 있더라도 검출되지 않아(II종 오류) 테스트가 실패할 수 있으므로, 미리 충분한 사용자 수나 기간을 확보해야 합니다invespcro.cominvespcro.com. 일반적으로 표본수가 많을수록 오차(margin of error)가 줄어들어 결과의 신뢰도가 높아지지만, 너무 크면 리소스·시간 비용이 증가합니다invespcro.cominvespcro.com.
실험 종료 후에는 **p-값(p-value)**과 **신뢰구간(confidence interval)**으로 결과를 해석합니다. p-값은 귀무가설(기본 버전과 개선 버전의 효과 차이가 없음)하에서 현재 결과가 나올 확률을 의미하며, p < 0.05(5%)면 통계적으로 유의하다고 판단합니다. 또한 각 군의 전환율 차이를 %포인트로 계산해 효과 크기를 직관적으로 평가합니다. 예를 들어, A그룹의 전환율이 30% → B그룹이 35%라면 5%p 증가입니다. B가 A보다 통계적으로 유의미한지 알아보려면 두 전환율 간의 신뢰구간을 구해 겹침 여부를 확인합니다. 전환율 같은 비율의 신뢰구간은 보통 $\hat{p} \pm z_{\alpha/2}\sqrt{\frac{\hat{p}(1-\hat{p})}{n}}$로 계산하며stats.libretexts.org, 예컨대 95% 신뢰수준(유의수준 5%)으로 구합니다. 95% 신뢰구간이면 “귀무가설이 맞을 때 이 정도 결과가 나올 확률이 5%”라는 의미입니다yozm.wishket.commedium.com. 신뢰구간이 겹치지 않거나 p-값이 임계값 이하이면 개선안(B)이 통계적으로 유의미하게 우수하다고 볼 수 있습니다.
시각적으로는 **신뢰구간(error bar)**를 함께 그린 그래프가 직관적입니다. 예를 들어 아래 그림은 A/B 양 군의 전환율과 그 90% CI를 보여줍니다. B의 전환율이 A의 CI 영역 밖에 위치하면(녹색 영역) 우수함을 의미합니다cxl.com. 빨간 영역에 있을 경우엔 B가 통계적으로 열등함을 뜻합니다.

그림: A/B 테스트 결과 예시(두 변형의 전환율과 신뢰구간). B 변형의 전환율(초록 실선)이 A의 신뢰구간(점선)을 넘어 있으므로 유의미한 개선으로 판단할 수 있다cxl.com.
또한 A/B 테스트에서는 통계적 검정력(power) 개념도 챙겨야 합니다. 보통 80~90%의 검정력을 목표로 삼아 표본 크기를 산정합니다. 이를 통해 실제 효과가 있을 때 이를 검출하지 못할 확률(II종 오류)을 낮출 수 있습니다. 한편, p-값이 통계적 유의성만 보여줄 뿐 실제 비즈니스 효과가 미미할 수도 있으므로, 절대/상대 효과 크기와 비즈니스 임팩트도 함께 고려하여 결과를 해석하는 것이 중요합니다.
3. 백엔드·앱 성능 지표의 통계적 이해
서버/앱 성능 지표(응답속도, 처리량, 오류율 등)는 데이터 분포 특성을 고려하여 해석해야 합니다. 응답시간(latency) 같은 경우, 데이터가 한쪽으로 긴 꼬리를 가지는 경우가 많아 평균보다는 **중앙값(median)**과 백분위수(percentile)가 유용합니다. 중앙값은 이상치에 영향을 덜 받기 때문에 “전형적인” 값으로 적합하며, P95 또는 P99 같은 퍼센타일은 상위 5%, 1% 사용자가 체감하는 “꼬리 시간”을 알려줍니다gatling.io. 예를 들어 “95th percentile latency가 1000ms”면 사용자 95%가 1000ms 이하로 응답받았음을 뜻합니다gatling.io. 이를 통해 대다수 사용자가 경험하는 빠른 응답과 소수만 경험하는 지연을 동시에 모니터링할 수 있습니다.
또한 평균과 중앙값은 왜도에 따라 다르게 나타납니다. 데이터가 오른쪽으로 치우치면(mean > median), 왼쪽으로 치우치면(mean < median) 형태가 됩니다openstax.org. 즉, 평균은 극단값(outlier)에 민감하므로 이상치가 많다면 중앙값이 대표성을 더 잘 보입니다. 예를 들어, 아래 히스토그램(그림)은 대칭/편향 분포 예시입니다. 중앙 막대들은 데이터가 6~8 사이에 몰려 있으며, 왼쪽 예시(그림1)는 대칭이지만 오른쪽(그림2, 3)은 꼬리가 왼쪽/오른쪽으로 길어 평균과 중앙값이 다르게 나타납니다openstax.orgopenstax.org.
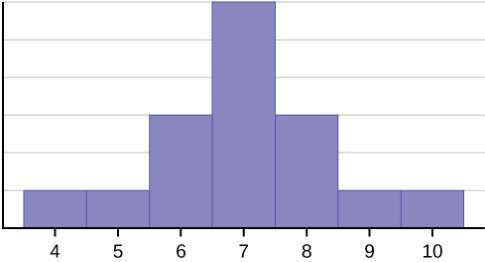
그림: 대칭 분포와 좌우비대칭(skewed) 분포 예시. 대칭 분포(왼쪽)에서는 평균≈중앙값이지만, 한쪽으로 치우친 분포(가운데, 오른쪽)에서는 평균과 중앙값의 위치가 달라짐을 보여준다openstax.orgopenstax.org.
성능 지표의 변동성 파악을 위해 **표준편차(standard deviation)**나 분산(variance)을 계산하기도 하지만, 분포가 비대칭일 때는 표준편차만으로는 꼬리 값을 설명하기 어렵습니다. 따라서 실제 성능 모니터링 시에는 히스토그램, CDF(누적분포), 박스플롯(boxplot) 등을 함께 사용하여 분포 특성을 시각화하고, 이상치나 꼬리(latency tail)를 종합적으로 파악하는 것이 좋습니다.
4. 핵심 지표(오류율·이탈률·전환률) 정의 및 해석
서비스 운영 중 자주 보는 KPI는 오류율, 사용자 이탈률(잔존율), 전환율 등이 있습니다. 이들의 정의와 신뢰구간 해석을 알아보겠습니다.
- 오류율(Error Rate): 전체 요청 중 실패한 요청(예: HTTP 5xx, 예외 등)이 차지하는 비율입니다. 예를 들어 오류율 = (오류 응답 수) / (전체 요청 수) ×100%로 정의합니다. 모니터링 시에는 RED(요청·오류·지연) 메소드에 따라, Errors(오류 건수)나 오류 비율로 표시하여 서비스 신뢰성을 평가합니다grafana.com. 오류율 역시 비율이므로 CI 계산 시 전환율과 같은 비율 공식 $\hat{p}(1-\hat{p})/n$을 적용할 수 있습니다.
- 이탈률(Churn Rate): 주로 특정 기간 내 서비스를 떠난(이탈한) 고객의 비율입니다. “서비스를 중단한 사용자 비율”이라고도 하며, 반대로 남아있는 비율을 **잔존율(retention rate)**이라 합니다. 예를 들어, 한 달 초에 1000명이던 사용자가 200명이 떠났다면 이달 이탈률은 20%(=200/1000)로, 잔존율은 80%입니다appsflyer.comappsflyer.com. 일반식은 (측정 시작 시점 사용자 수 – 종료 시점 사용자 수) / 시작 시점 사용자 수 ×100%입니다appsflyer.com. 이탈률이 높으면 신규 획득 비용이 증가하고 제품 접착력이 낮다는 신호이므로, 보통 90% 이상(이탈률 10% 이하)을 목표로 관리합니다.
- 전환율(Conversion Rate): 방문자 중에 목표 행위(구매, 회원가입, 클릭 등)를 완료한 비율입니다. 정의는 “웹사이트나 앱에 방문한 사람 중 유도된 행동을 한 사람의 비율”로, 마케팅·성장 지표의 기본입니다ko.wikipedia.org. 예를 들어 100명이 방문해서 5명이 구매했다면 전환율은 5%입니다. A/B 테스트나 캠페인 분석 시 전환율의 신뢰구간(오차범위)을 함께 보면 유의성과 불확실도를 해석할 수 있습니다. 전환율 $\hat p$의 95% 신뢰구간은 $\hat p \pm 1.96\sqrt{\frac{\hat p(1-\hat p)}{n}}$처럼 계산됩니다stats.libretexts.org. 예를 들어 전환율이 5%이고 표본이 1000명일 때, 대략의 신뢰구간은 $5%\pm1.96\sqrt{0.05\times0.95/1000}$ 정도입니다. 신뢰구간이 좁을수록 추정 정확도가 높고, 겹치지 않으면 두 시점 혹은 두 그룹 간 차이가 유의하다고 볼 수 있습니다.
추가로, 신뢰구간 해석에 주의해야 합니다. 흔히 “95% 신뢰구간”이 “모수가 해당 구간 안에 있을 확률이 95%”라 오해하지만, 이는 샘플링 절차에 대한 확률입니다. 실제로는 “95% 신뢰수준에서 구간을 구하면, 이 방법을 반복하면 95% 확률로 참값을 포함하는 구간이 나올 것”이라는 의미입니다yozm.wishket.com. 즉 “A와 B의 전환율 차이 0.5% (95% CI [0.1%,0.9%])”라면, 귀무가설(차이=0)일 때 이 정도 결과가 나올 확률(유의수준)은 5% 이하라는 뜻입니다yozm.wishket.com.
5. 통계 실험 및 지표 추적을 위한 데이터 구조
통계 기반 분석을 위해서는 데이터 모델링이 중요합니다. 일반적으로는 **이벤트 테이블(event fact table)**과 세션 테이블, 사용자 테이블 등의 구조를 사용합니다. 예를 들어 이벤트 테이블에는 개별 이벤트 하나하나를 식별할 수 있는 고유 ID와 시간(timestamp), 사용자 식별자(user_id), 이벤트 종류(name) 및 상세 속성(properties) 등을 기록합니다. Amplitude 같은 분석 플랫폼을 예로 들면, 이벤트 테이블을 일종의 팩트 테이블(fact table)으로 보며 고유 ID와 타임스탬프를 필수 컬럼으로 둡니다amplitude.combigquery.optizent.com. GA4 BigQuery 스키마에도 event_timestamp, event_name 같은 컬럼이 존재합니다bigquery.optizent.combigquery.optizent.com.
세션 테이블은 한 사용자의 연속된 이벤트 묶음을 나타냅니다. 일반적으로 이벤트 테이블의 user_id와 timestamp를 이용해 일정 시간(예: 30분) 이상 연속성이 끊기면 새로운 세션으로 구분합니다cube.dev. 세션 테이블에는 session_id, user_id, 세션 시작·종료 시각, 디바이스·채널 등 속성, 세션 길이나 이벤트 수 같은 지표를 두어 사용자 행동을 집계합니다. 분석 목적에 따라 사용자 테이블(가입일, 속성 등), 판매 테이블, 제품 테이블 등 차원 테이블(dim table)과 조합하기도 합니다.
예시를 들어 데이터 웨어하우스 모델을 간략화하면 다음과 같습니다:
| 이벤트 테이블 | event_id, user_id, timestamp, event_name, ... | 사용자가 발생시킨 개별 행동을 기록(예: 클릭, 페이지뷰 등) |
| 세션 테이블 | session_id, user_id, start_time, end_time, event_count, ... | 같은 사용자의 일련의 행동 묶음(세션) 정보 저장 |
| 사용자 테이블 | user_id, signup_date, properties | 사용자의 속성·프로파일 정보 저장 |
이처럼 구조화된 테이블을 기반으로 통계적 실험(예: A/B 그룹별 유입)을 위한 지표(일/주/월별 전환율, MAU, 잔존율 등)를 집계하고 추적하면, 데이터 기반 의사결정을 효율적으로 수행할 수 있습니다.
6. 실무 예시와 시각화
위에서 설명한 개념들을 실제로 적용한 사례와 시각화를 통해 이해를 돕습니다. 예를 들어, 사용자 이벤트의 분포를 시각화한 히스토그램을 보면 데이터가 대칭인지, 치우침이 심한지를 쉽게 파악할 수 있습니다. 아래 그림은 대칭형(왼쪽)과 한쪽으로 꼬리가 긴 분포(가운데, 오른쪽)의 예시로, 평균(mean)과 중앙값(median)의 관계 변화를 보여줍니다openstax.orgopenstax.org.
또 다른 예로 A/B 테스트 결과의 시각화를 들 수 있습니다. 앞에서 본 예시 그림【78†】과 같이 두 변형(A, B)의 주요 지표(전환율, 오류율 등)를 점과 신뢰구간으로 표현하면 결과를 한눈에 이해하기 쉽습니다. B 변형의 성능이 A 변형의 신뢰구간을 벗어나 있으면 통계적으로 유의한 개선으로 해석할 수 있습니다cxl.com. 이처럼 실제 데이터를 그래프로 표현하면 팀이나 경영진에게 결과를 효과적으로 전달하고, 개선 포인트를 직관적으로 파악하는 데 도움이 됩니다.
각 개념은 실제 사례에 맞추어 유연하게 적용해야 합니다. 예를 들어 A/B 테스트에서는 위 예시처럼 전환율 그래프나 콘피던스 인터벌 차트를 사용하며, 성능 모니터링 대시보드에서는 P95 레이턴시나 이상치 타임라인 차트를 추가로 표시할 수 있습니다. 데이터 구조 설계 시에도 각 지표를 계산할 수 있는 충분한 컬럼(예: 사용자 식별자, 타임스탬프, 이벤트 파라미터 등)이 포함되었는지 검토해야 합니다. 이러한 통계적·구조적 준비를 통해 백엔드와 앱 개발자는 사용자 행동과 시스템 성능을 깊이 있게 이해하고, 데이터 기반으로 제품을 개선할 수 있습니다.
출처: 데이터 분석 및 A/B 테스트 관련 통계 지식double-d.tistory.comopenstax.orggatling.ioappsflyer.comko.wikipedia.orgstats.libretexts.orgamplitude.comcube.devbigquery.optizent.comvelog.iovelog.iomedium.cominvespcro.cominvespcro.com. 각 그림 출처는 설명에 기재된 링크 참고.
'Research > Study' 카테고리의 다른 글
| [2025.06.29]웹 서버 처리 구조(TCP) (0) | 2025.06.29 |
|---|---|
| [2025.06.01] System call 호출 흐름 (0) | 2025.06.01 |
| [2025.06.01] 레지스트리 편집기 (0) | 2025.06.01 |
| [250529] MCP(모델 컨텍스트 프로토콜) 개요 (0) | 2025.05.29 |
| [Deep research][250506] Linux/QNX 환경의 C++ 보안 취약점 분석 가이드 (1) | 2025.05.06 |
